

Hay un momento en cualquier incursión en un nuevo territorio tecnológico en el que se da cuenta de que puede haberse embarcado en una tarea de Sísifo. Mirando la multitud de opciones disponibles para asumir el proyecto, investigas tus opciones, lees la documentación y comienzas a trabajar, solo para descubrir que en realidad solo definiendo el problema puede ser más trabajo que encontrar la solución real.
Lector, aquí es donde me encontré dos semanas en esta aventura en el aprendizaje automático. Me familiaricé con los datos, las herramientas y los enfoques conocidos de problemas con este tipo de datos, y probé varios enfoques para resolver lo que en la superficie parecía ser un simple problema de aprendizaje automático: basándonos en el rendimiento pasado, ¿podríamos predecir si algún titular de Ars dado será un ganador en una prueba A / B?
Las cosas no han ido particularmente bien. De hecho, cuando terminé esta pieza, mi intento más reciente mostró que nuestro algoritmo era tan preciso como el lanzamiento de una moneda.
Pero al menos eso fue un comienzo. Y en el proceso de llegar allí, aprendí mucho sobre la limpieza y el preprocesamiento de datos que se incluyen en cualquier proyecto de aprendizaje automático.
Preparando el campo de batalla
Nuestra fuente de datos es un registro de los resultados de más de 5.500 pruebas A / B de titulares durante los últimos cinco años; eso es aproximadamente el tiempo que Ars ha estado haciendo este tipo de tiroteo de titulares para cada historia que se publica. Dado que tenemos etiquetas para todos estos datos (es decir, sabemos si ganó o perdió su prueba A / B), esto parecería ser una problema de aprendizaje supervisado. Todo lo que realmente necesitaba hacer para preparar los datos era asegurarme de que tuvieran el formato adecuado para el modelo que elegí usar para crear nuestro algoritmo.
No soy un científico de datos, por lo que no iba a construir mi propio modelo en ningún momento de esta década. Afortunadamente, AWS proporciona una serie de modelos prediseñados adecuados para la tarea de procesar texto y diseñados específicamente para funcionar dentro de los límites de la nube de Amazon. También hay modelos de terceros, como Abrazando la cara, que se puede utilizar dentro del Universo SageMaker. Cada modelo parece necesitar que se le proporcionen datos de una manera particular.
La elección del modelo en este caso se reduce en gran medida al enfoque que adoptemos para resolver el problema. Inicialmente, vi dos enfoques posibles para entrenar un algoritmo para obtener una probabilidad de éxito de cualquier titular:
- Clasificación binaria: Simplemente determinamos cuál es la probabilidad de que el titular caiga en la columna de “ganar” o “perder” en función de los ganadores y perdedores anteriores. Podemos comparar la probabilidad de dos titulares y elegir el candidato más fuerte.
- Clasificación de categorías múltiples: Intentamos clasificar los titulares en función de su tasa de clics en varias categorías, por ejemplo, clasificándolos de 1 a 5 estrellas. A continuación, podríamos comparar las puntuaciones de los candidatos a titulares.
El segundo enfoque es mucho más difícil, y hay una preocupación general con cualquiera de estos métodos que hace que el segundo sea aún menos sostenible: 5.500 pruebas, con 11.000 titulares, no son muchos datos para trabajar en el gran esquema de IA / ML de cosas.
Así que opté por la clasificación binaria para mi primer intento, porque parecía el más probable de éxito. También significó que el único punto de datos que necesitaba para cada título (al lado del título en sí) es si ganó o perdió la prueba A / B. Tomé mis datos de origen y los reformateé en un archivo de valores separados por comas con dos columnas: títulos en una y “sí” o “no” en la otra. También utilicé un script para eliminar todo el marcado HTML de los titulares (principalmente algunas etiquetas y algunas ). Con los datos reducidos casi hasta lo esencial, los cargué en SageMaker Studio para poder usar las herramientas de Python para el resto de la preparación.
A continuación, necesitaba elegir el tipo de modelo y preparar los datos. Una vez más, gran parte de la preparación de los datos depende del tipo de modelo en el que se introducirán los datos. Diferentes tipos de procesamiento natural del lenguaje los modelos (y problemas) requieren diferentes niveles de preparación de datos.
Después de eso viene la “tokenización”. El evangelista tecnológico de AWS, Julien Simon, lo explica de la siguiente manera: “El procesamiento de datos primero debe reemplazar las palabras con tokens, tokens individuales”. Un token es un número legible por máquina que representa una cadena de caracteres. “Entonces, ‘ransomware’ sería la palabra uno”, dijo, “‘delincuentes’ sería la palabra dos, ‘configuración’ sería la palabra tres … así que una oración se convierte en una secuencia de tokens y puedes alimentar eso a un aprendizaje profundo modelar y dejar que aprenda cuáles son los buenos, cuáles son los malos “.
Dependiendo del problema particular, es posible que desee deshacerse de algunos de los datos. Por ejemplo, si intentáramos hacer algo como análisis de los sentimientos (es decir, determinar si un título Ars determinado tiene un tono positivo o negativo) o agrupar los títulos por su tema, probablemente querría recortar los datos al contenido más relevante eliminando las “palabras vacías”, palabras comunes que son importantes para la estructura gramatical, pero no le dicen lo que el texto realmente dice (como la mayoría artículos).
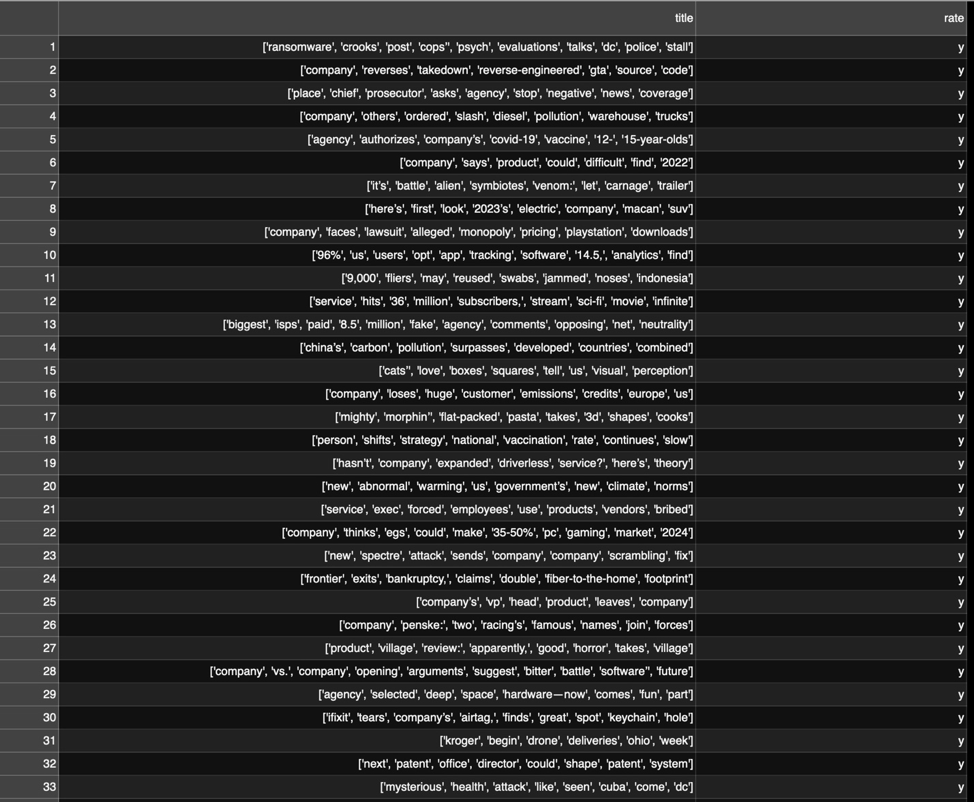
nltk). Observe que la puntuación a veces se empaqueta con palabras como símbolo; esto tendría que limpiarse para algunos casos de uso.Sin embargo, en este caso, las palabras vacías eran partes potencialmente importantes de los datos; después de todo, estamos buscando estructuras de titulares que llamen la atención. Así que opté por mantener todas las palabras. Y en mi primer intento de entrenamiento, decidí usar BlazingText, un modelo de procesamiento de texto que AWS demuestra en un problema de clasificación similar al que estamos intentando. BlazingText requiere que los datos de la “etiqueta”, los datos que indican la clasificación de un texto en particular, estén precedidos por “__label__“. Y en lugar de un archivo delimitado por comas, los datos de la etiqueta y el texto a procesar se colocan en una sola línea en un archivo de texto, así:
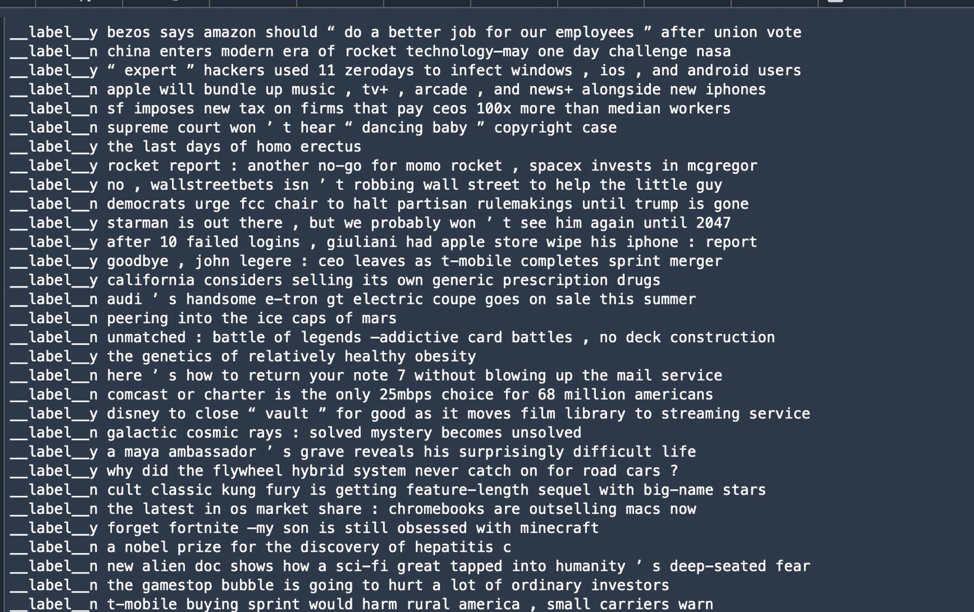
Otra parte del preprocesamiento de datos para el aprendizaje supervisado del aprendizaje automático es dividir los datos en dos conjuntos: uno para entrenar el algoritmo y otro para la validación de sus resultados. El conjunto de datos de entrenamiento suele ser el conjunto más grande. Los datos de validación generalmente se crean a partir de alrededor del 10 al 20 por ciento de los datos totales.
Hay ha sido una gran cantidad de investigación en lo que es realmente la cantidad correcta de datos de validación; parte de esa investigación sugiere que el punto óptimo se relaciona más con la cantidad de parámetros del modelo que se utilizan para crear el algoritmo que con el tamaño general de los datos. En este caso, dado que el modelo tenía que procesar relativamente pocos datos, supuse que mis datos de validación serían del 10 por ciento.
En algunos casos, es posible que desee retener otro pequeño grupo de datos para probar el algoritmo después está validado. Pero nuestro plan aquí es usar los titulares de Ars en vivo para probar, así que me salté ese paso.
Para hacer mi preparación de datos final, utilicé un Cuaderno Jupyter—Una interfaz web interactiva para una instancia de Python— para convertir mi CSV de dos columnas en una estructura de datos y procesarlo. Python tiene algunos juegos de herramientas decentes para la manipulación de datos y la ciencia de datos que hacen que estas tareas sean bastante sencillas, y usé dos en particular aquí:
pandas, un popular módulo de análisis y manipulación de datos que hace maravillas cortando y cortando archivos CSV y otros formatos de datos comunes.sklearn(oscikit-learn), un módulo de ciencia de datos que elimina gran parte del trabajo pesado del preprocesamiento de datos de aprendizaje automático.nltk, el Kit de herramientas de lenguaje natural, y específicamente, elPunkttokenizador de frases para procesar el texto de nuestros titulares.- La
csvmódulo para leer y escribir archivos CSV.
Aquí hay una parte del código en el cuaderno que usé para crear mis conjuntos de entrenamiento y validación a partir de nuestros datos CSV:
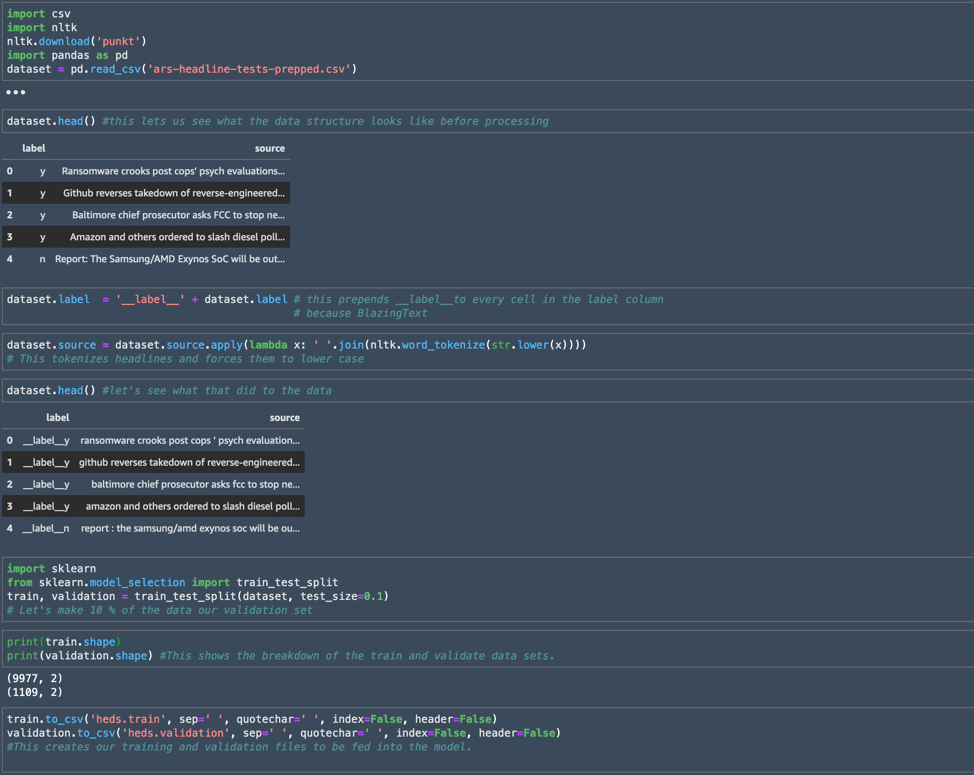
Empecé usando pandas para importar la estructura de datos del CSV creado a partir de los datos inicialmente limpiados y formateados, llamando al objeto resultante “conjunto de datos”. Utilizando la dataset.head() El comando me dio un vistazo a los encabezados de cada columna que se había traído desde el CSV, junto con un vistazo a algunos de los datos.
El módulo de pandas me permitió agregar masivamente la cadena “__label__“a todos los valores en la columna de la etiqueta como lo requiere BlazingText, y usé un función lambda para procesar los titulares y forzar todas las palabras a minúsculas. Finalmente, utilicé el sklearn módulo para dividir los datos en los dos archivos que enviaría a BlazingText.