Como funcionan los bits
Probablemente hayas escuchado antes que las computadoras almacenan cosas en 1sy 0s. Estas unidades fundamentales de información se conocen como bits. Cuando un bit está “activado”, se corresponde con un 1; cuando está “apagado”, se convierte en un 0. Cada bit, en otras palabras, puede almacenar solo dos piezas de información.
Pero una vez que los une, la cantidad de información que puede codificar crece exponencialmente. Dos bits pueden representar cuatro piezas de información porque hay 2 ^ 2 combinaciones: 00, 01, 10y 11. Cuatro bits pueden representar 2 ^ 4 o 16 piezas de información. Ocho bits pueden representar 2 ^ 8 o 256. Y así sucesivamente.
La combinación correcta de bits puede representar tipos de datos como números, letras y colores, o tipos de operaciones como suma, resta y comparación. La mayoría de las computadoras portátiles en estos días son computadoras de 32 o 64 bits. Eso no significa que la computadora solo pueda codificar 2 ^ 32 o 2 ^ 64 piezas de información en total. (Sería una computadora muy débil). Significa que puede usar esa cantidad de bits de complejidad para codificar cada pieza de datos u operación individual.
Aprendizaje profundo de 4 bits
Entonces, ¿qué significa el entrenamiento de 4 bits? Bueno, para empezar, tenemos una computadora de 4 bits y, por lo tanto, 4 bits de complejidad. Una forma de pensar en esto: cada número que usamos durante el proceso de entrenamiento tiene que ser uno de 16 números enteros entre -8 y 7, porque estos son los únicos números que nuestra computadora puede representar. Eso se aplica a los p untos de datos que alimentamos a la red neuronal, los números que usamos para representar la red neuronal y los números intermedios que necesitamos almacenar durante el entrenamiento.
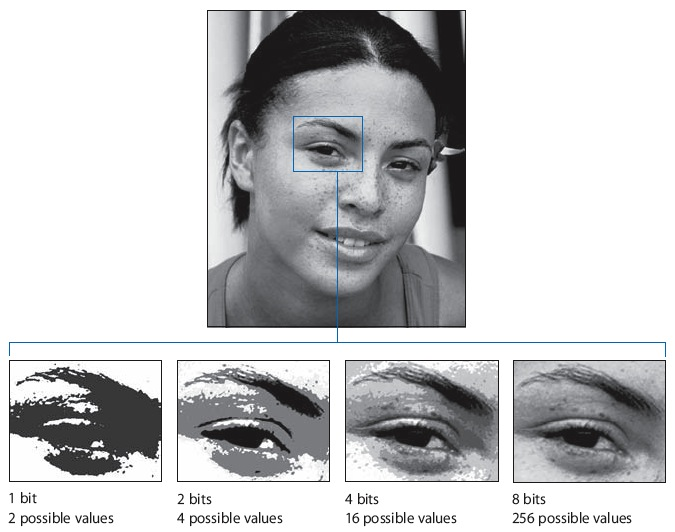
¿Entonces como hacemos esto? Primero pensemos en los datos de entrenamiento. Imagina que es un montón de imágenes en blanco y negro. Paso uno: necesitamos convertir esas imágenes en números, para que la computadora pueda entenderlas. Hacemos esto representando cada píxel en términos de su valor de escala de grises: 0 para el negro, 1 para el blanco y los decimales intermedios para los tonos de gris. Nuestra imagen ahora es una lista de números que van del 0 al 1. Pero en el terreno de 4 bits, necesitamos que tenga un rango de -8 a 7. El truco aquí es escalar linealmente nuestra lista de números, por lo que 0 se convierte en -8 1 se convierte en 7 y los decimales se asignan a los enteros del medio. Entonces:

Este proceso no es perfecto. Si comenzara con el número 0.3, digamos, terminaría con el número escalado -3.5. Pero nuestros cuatro bits solo pueden representar números enteros, por lo que debe redondear -3,5 a -4. Terminas perdiendo algunos de los tonos grises, o los llamados precisión, a tu imagen. Puedes ver cómo se ve en la imagen de abajo.
Este truco no está nada mal para los datos de entrenamiento. Pero cuando lo aplicamos nuevamente a la propia red neuronal, las cosas se complican un poco más.

A menudo vemos redes neuronales dibujadas como algo con nodos y conexiones, como la imagen de arriba. Pero para una computadora, estos también se convierten en una serie de números. Cada nodo tiene un llamado activación valor, que suele oscilar entre 0 y 1, y cada conexión tiene un peso, que suele oscilar entre -1 y 1.
Podríamos escalarlos de la misma manera que lo hicimos con nuestros píxeles, pero las activaciones y los pesos también cambian con cada ronda de entrenamiento. Por ejemplo, a veces las activaciones varían de 0,2 a 0,9 en una ronda y de 0,1 a 0,7 en otra. Entonces, el grupo de IBM descubrió un nuevo truco en 2018: reescalar esos rangos para que se extiendan entre -8 y 7 en cada ronda (como se muestra a continuación), lo que efectivamente evita perder demasiada precisión.

Pero luego nos quedamos con una pieza final: cómo representar en cuatro bits los valores intermedios que surgen durante el entrenamiento. El desafío es que estos valores pueden abarcar varios órdenes de magnitud, a diferencia de los números que manejamos para nuestras imágenes, pesos y activaciones. Pueden ser pequeños, como 0,001, o enormes, como 1000. Tratar de escalar linealmente esto entre -8 y 7 pierde toda la granularidad en el extremo diminuto de la escala.

Después de dos años de investigación, los investigadores finalmente resolvieron el rompecabezas: tomando prestada una idea existente de otros, escalan estos números intermedios logarítmicamente. Para ver lo que quiero decir, a continuación se muestra una escala logarítmica que quizás reconozca, con una denominada “base” de 10, que utiliza solo cuatro bits de complejidad. (En su lugar, los investigadores utilizan una base de 4, porque la prueba y el error demostraron que esto funcionaba mejor). Puede ver cómo le permite codificar números pequeños y grandes dentro de las restricciones de bits.

Con todas estas piezas en su lugar, este último artículo muestra cómo se unen. Los investigadores de IBM realizan varios experimentos en los que simulan el entrenamiento de 4 bits para una variedad de modelos de aprendizaje profundo en la visión por computadora, el habla y el procesamiento del lenguaje natural. Los resultados muestran una pérdida limitada de precisión en el rendimiento general de los modelos en comparación con el aprendizaje profundo de 16 bits. El proceso también es siete veces más rápido y siete veces más eficiente energéticamente.