Aurich Lawson | imágenes falsas
No soy un científico de datos. Y aunque sé manejar un cuaderno de Jupyter y he escrito una buena cantidad de código de Python, no pretendo ser nada parecido a un experto en aprendizaje automático. Entonces, cuando realicé la primera parte de nuestro experimento de aprendizaje automático sin código/de código bajo y obtuve una tasa de precisión superior al 90 por ciento en un modelo, sospeché que había hecho algo mal.
Si no ha estado siguiendo hasta ahora, aquí hay una revisión rápida antes de que lo dirija de nuevo a los dos primeros artículos de esta serie. Para ver cuánto habían avanzado las herramientas de aprendizaje automático para el resto de nosotros, y para redimirme de la tarea imposible de ganar que me habían asignado con el aprendizaje automático el año pasado, tomé un conjunto de datos de ataques cardíacos desgastados de un archivo en la Universidad de California-Irvine e intentó superar los resultados de los estudiantes de ciencia de datos utilizando el “botón fácil” de las herramientas de código bajo y sin código de Amazon Web Services.
El objetivo de este experimento era ver:
- Si un novato relativo podría usar estas herramientas de manera efectiva y precisa
- Si las herramientas eran más rentables que encontrar a alguien que supiera qué diablos estaban haciendo y entregárselo.
Esa no es exactamente una imagen real de cómo suelen ocurrir los proyectos de aprendizaje automático. Y como descubrí, la opción “sin código” que ofrece Amazon Web Services:Lienzo de SageMaker—está destinado a trabajar de la mano con el enfoque más científico de datos de Estudio SageMaker. Pero Canvas superó lo que pude hacer con el enfoque de código bajo de Studio, aunque probablemente debido a mis manos poco hábiles en el manejo de datos.
(Para aquellos que no han leído los dos artículos anteriores, ahora es el momento de ponerse al día: aquí está la primera parte y aquí la segunda parte).
Evaluación del trabajo del robot.
Canvas me permitió exportar un enlace para compartir que abrió el modelo que creé con mi compilación completa a partir de más de 590 filas de datos de pacientes de la Clínica Cleveland y el Instituto Húngaro de Cardiología. Ese enlace me dio un poco más de información sobre lo que sucedía dentro de la caja muy negra de Canvas con Studio, un basado en Jupyter plataforma para hacer ciencia de datos y experimentos de aprendizaje automático.
Como su nombre sugiere astutamente, Jupyter está basado en Python. Es una interfaz basada en la web para un entorno de contenedor que le permite activar núcleos basados en diferentes implementaciones de Python, según la tarea.
Ejemplos de los diferentes contenedores de kernel disponibles en Studio.
Los núcleos se pueden completar con cualquier módulo que requiera el proyecto cuando realiza exploraciones centradas en el código, como la biblioteca de análisis de datos de Python (pandas) y SciKit-Learn (aprendió). Usé una versión local de Jupyter Lab para realizar la mayor parte de mi análisis de datos inicial para ahorrar tiempo de cómputo en AWS.
El entorno de Studio creado con el enlace de Canvas incluía contenido preconstruido que brindaba información sobre el modelo que produjo Canvas, algo de lo cual discutí brevemente en el último artículo:

Algunos de los detalles incluyeron los hiperparámetros utilizados por la versión mejor ajustada del modelo creado por Canvas:
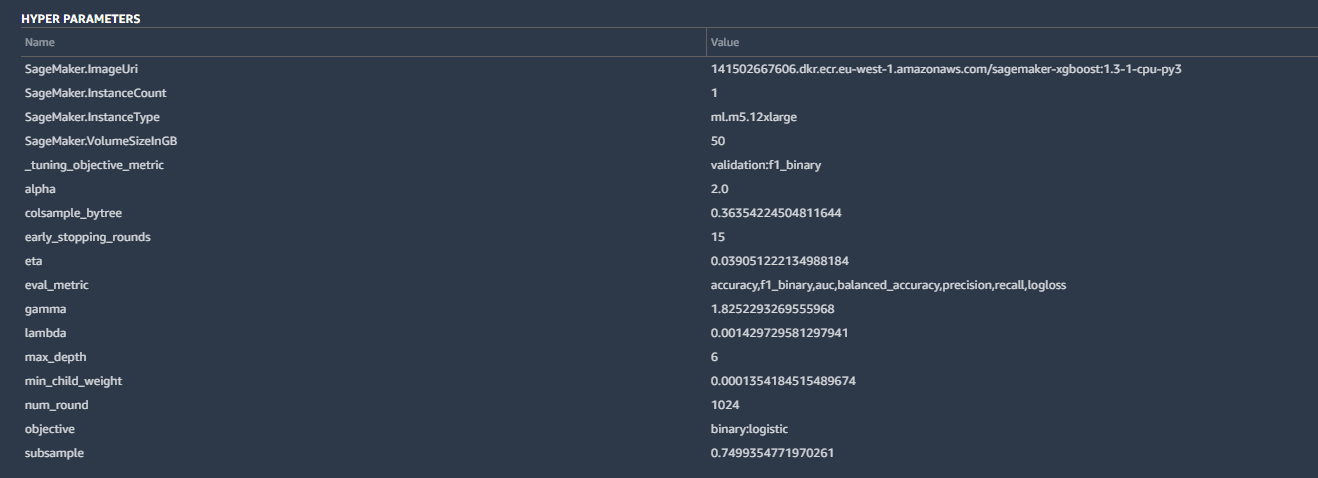
Los hiperparámetros son ajustes que AutoML realizó en los cálculos del algoritmo para mejorar la precisión, así como algunas tareas básicas de mantenimiento: los parámetros de la instancia de SageMaker, la métrica de ajuste (“F1”, que analizaremos en un momento) y otras entradas. Todos estos son bastante estándar para una clasificación binaria como la nuestra.
La descripción general del modelo en Studio proporcionó información básica sobre el modelo producido por Canvas, incluido el algoritmo utilizado (XGBoost) y la importancia relativa de cada una de las columnas calificadas con algo llamado valores SHAP. SHAP es un acrónimo realmente horrible que significa “SHapley Additive exPlanations”, que es un teoría de juegobasado en un método para extraer la contribución de cada característica de datos a un cambio en la salida del modelo. Resulta que “frecuencia cardíaca máxima alcanzada” tuvo un impacto insignificante en el modelo, mientras que talasemia (“thall”) y los resultados del angiograma (“caa”), puntos de datos para los que teníamos datos faltantes significativos, tuvieron más impacto del que yo quería. No podía dejarlos caer, aparentemente. Así que descargué un informe de rendimiento del modelo para obtener información más detallada sobre cómo se mantuvo el modelo: