Benj Edwards / Ars Technica
El miércoles, OpenAI lanzó un nuevo modelo de IA de código abierto llamado Susurro que reconoce y traduce audio a un nivel que se acerca a la capacidad de reconocimiento humano. Puede transcribir entrevistas, podcasts, conversaciones y más.
IA abierta susurro entrenado en 680.000 horas de datos de audio y transcripciones coincidentes en aproximadamente 10 idiomas recopilados de la web. Según OpenAI, este enfoque de colección abierta ha llevado a “una mayor solidez de los acentos, el ruido de fondo y el lenguaje técnico”. También puede detectar el idioma hablado y traducirlo al inglés.
OpenAI describe Whisper como un transformador codificador-decodificador, un tipo de red neuronal que puede usar el contexto extraído de los datos de entrada para aprender asociaciones que luego se pueden traducir a la salida del modelo. OpenAI presenta esta descripción general de la operación de Whisper:
El audio de entrada se divide en fragmentos de 30 segundos, se convierte en un espectrograma log-Mel y luego se pasa a un codificador. Se entrena un decodificador para predecir el subtítulo de texto correspondiente, entremezclado con tokens especiales que dirigen al modelo único para realizar tareas como identificación de idioma, marcas de tiempo a nivel de frase, transcripción de voz multilingüe y traducción de voz al inglés.
Al abrir Whisper, OpenAI espera introducir un nuevo modelo básico que otros puedan aprovechar en el futuro para mejorar el procesamiento del habla y las herramientas de accesibilidad. OpenAI tiene un historial significativo en este frente. En enero de 2021, OpenAI lanzó ACORTARun modelo de visión por computadora de código abierto que podría decirse que inició la era reciente de la tecnología de síntesis de imágenes que avanza rápidamente, como DALL-E 2 y Stable Diffusion.
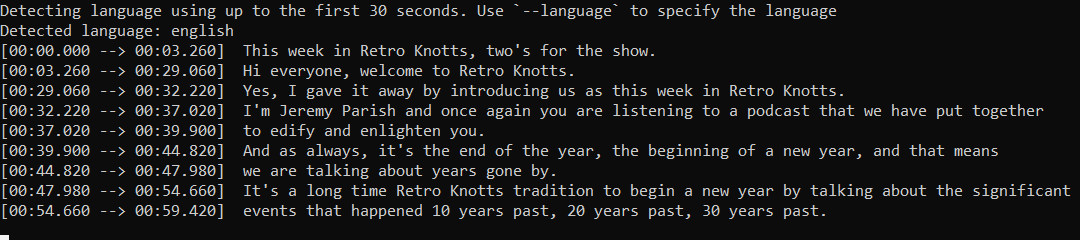
En Ars Technica, probamos Whisper desde el código disponible en GitHub, y lo alimentamos con múltiples muestras, incluido un episodio de podcast y una sección de audio particularmente difícil de entender tomada de una entrevista telefónica. Aunque tomó algo de tiempo mientras se ejecutaba a través de una CPU de escritorio Intel estándar (la tecnología aún no funciona en tiempo real), Whisper hizo un buen trabajo al transcribir el audio a texto a través del programa Python de demostración, mucho mejor que algunos programas impulsados por inteligencia artificial. servicios de transcripción de audio que hemos probado en el pasado.
Benj Edwards / Ars Technica
Con la configuración adecuada, Whisper podría usarse fácilmente para transcribir entrevistas, podcasts y, potencialmente, traducir podcasts producidos en idiomas distintos del inglés al inglés en su máquina, de forma gratuita. Esa es una combinación potente que eventualmente podría alterar la industria de la transcripción.
Al igual que con casi todos los nuevos modelos importantes de IA en estos días, Whisper brinda ventajas positivas y el potencial de uso indebido. en susurro modelo de tarjeta (en la sección “Implicaciones más amplias”), OpenAI advierte que Whisper podría usarse para automatizar la vigilancia o identificar a hablantes individuales en una conversación, pero la compañía espera que se use “principalmente con fines beneficiosos”.