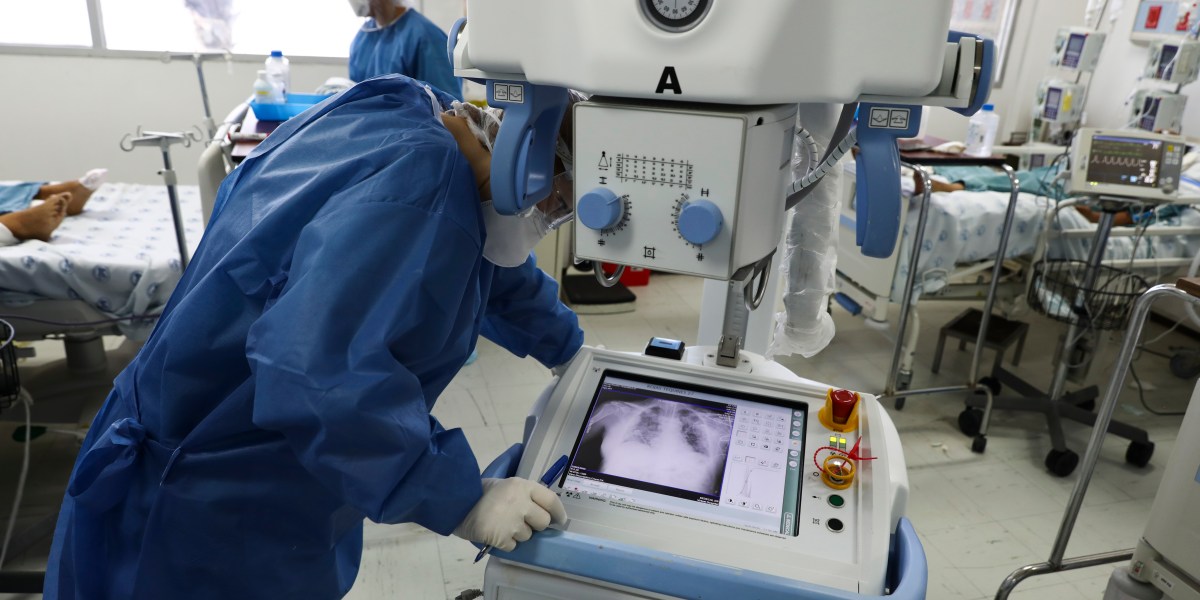
También enturbia el origen de ciertos conjuntos de datos. Esto puede significar que los investigadores pasan por alto características importantes que sesgan el entrenamiento de sus modelos. Muchos usaron sin saberlo un conjunto de datos que contenía escáneres de tórax de niños que no tenían covid como ejemplos de cómo se veían los casos sin covid. Pero como resultado, las IA aprendieron a identificar a los niños, no a los covid.
El grupo de Driggs entrenó su propio modelo utilizando un conjunto de datos que contenía una combinación de exploraciones tomadas cuando los pacientes estaban acostados y de pie. Debido a que los pacientes escaneados mientras estaban acostados tenían más probabilidades de estar gravemente enfermos, la IA aprendió erróneamente a predecir el riesgo de covid grave desde la posición de una persona.
En otros casos, se descubrió que algunas IA detectaban la fuente del texto que ciertos hospitales usaban para etiquetar los escaneos. Como resultado, las fuentes de los hospitales con una carga de casos más grave se convirtieron en predictores del riesgo de covid.
Errores como estos parecen obvios en retrospectiva. También pueden solucionarse ajustando los modelos, si los investigadores los conocen. Es posible reconocer las deficiencias y publicar un modelo menos preciso, pero menos engañoso. Pero muchas herramientas fueron desarrolladas por investigadores de IA que carecían de la experiencia médica para detectar fallas en los datos o por investigadores médicos que carecían de las habilidades matemáticas para compensar esas fallas.
Un problema más sutil que Driggs destaca es el sesgo de incorporación, o sesgo introducido en el punto en el que se etiqueta un conjunto de datos. Por ejemplo, muchos escáneres médicos se etiquetaron según si los radiólogos que los crearon dijeron que mostraban covid. Pero eso incrusta, o incorpora, cualquier sesgo de ese médico en particular en la verdad básica de un conjunto de datos. Sería mucho mejor etiquetar una exploración médica con el resultado de una prueba de PCR en lugar de la opinión de un médico, dice Driggs. Pero no siempre hay tiempo para sutilezas estadísticas en hospitales ocupados.
Eso no ha impedido que algunas de estas herramientas se introduzcan rápidamente en la práctica clínica. Wynants dice que no está claro cuáles se están utilizando ni cómo. Los hospitales a veces dirán que están usando una herramienta solo con fines de investigación, lo que dificulta evaluar cuánto confían los médicos en ellos. “Hay mucho secreto”, dice.
Wynants le pidió a una empresa que comercializaba algoritmos de aprendizaje profundo que compartiera información sobre su enfoque, pero no recibió respuesta. Posteriormente encontró varios modelos publicados por investigadores vinculados a esta empresa, todos ellos con un alto riesgo de sesgo. “En realidad, no sabemos qué implementó la empresa”, dice.
Según Wynants, algunos hospitales incluso están firmando acuerdos de no divulgación con proveedores de IA médica. Cuando les preguntó a los médicos qué algoritmos o software estaban usando, a veces le dijeron que no se les permitía decirlo.
Como arreglarlo
¿Cuál es la solución? Una mejor información ayudaría, pero en tiempos de crisis esa es una gran pregunta. Es más importante aprovechar al máximo los conjuntos de datos que tenemos. El movimiento más simple sería que los equipos de inteligencia artificial colaboraran más con los médicos, dice Driggs. Los investigadores también deben compartir sus modelos y revelar cómo fueron capacitados para que otros puedan probarlos y desarrollarlos. “Esas son dos cosas que podríamos hacer hoy”, dice. “Y resolverían quizás el 50% de los problemas que identificamos”.
Obtener datos también sería más fácil si los formatos estuvieran estandarizados, dice Bilal Mateen, un médico que lidera la investigación en tecnología clínica en Wellcome Trust, una organización benéfica de investigación de salud global con sede en Londres.