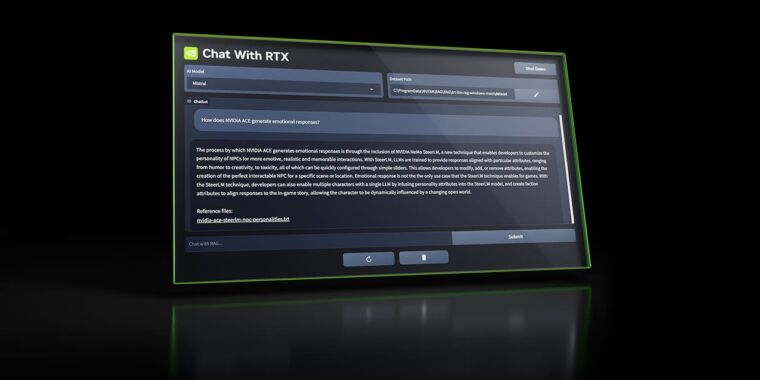
El martes, Nvidia liberado Chat With RTX, un chatbot de IA personalizado y gratuito similar a ChatGPT que puede ejecutarse localmente en una PC con una tarjeta gráfica Nvidia RTX. Utiliza LLM de peso abierto Mistral o Llama y puede buscar en archivos locales y responder preguntas sobre ellos.
Además, la aplicación admite una variedad de formatos de archivo, incluidos .TXT, .PDF, .DOCX y .XML. Los usuarios pueden dirigir la herramienta para que explore carpetas específicas, que Chat With RTX luego escanea para responder consultas rápidamente. Incluso permite incorporar información de vídeos y listas de reproducción de YouTube, ofreciendo una forma de incluir contenido externo en su base de datos de conocimiento (en forma de incrustaciones) sin necesidad de conexión a Internet para procesar consultas.
Áspero alrededor de los bordes
Descargamos y ejecutamos Chat With RTX para probarlo. El archivo de descarga es enorme, alrededor de 35 gigabytes, debido a que los archivos de pesos de Mistral y Llama LLM se incluyen en la distribución. (“Pesos” son los archivos reales de la red neuronal que contienen los valores que representan los datos aprendidos durante el proceso de entrenamiento de IA). Al instalar, Chat With RTX descarga aún más archivos y se ejecuta en una ventana de consola usando Python con una interfaz que aparece en una ventana del navegador web.
Varias veces durante nuestras pruebas en un RTX 3060 con 12 GB de VRAM, Chat With RTX falló. Al igual que las interfaces LLM de código abierto, Chat With RTX es un lío de dependencias en capas que se basan en Python, CUDA, TensorRT y otros. Nvidia no ha descifrado el código para que la instalación sea elegante y no frágil. Es una solución tosca que se parece mucho a una máscara de Nvidia sobre otras interfaces LLM locales (como GPT4ALL). Aun así, es notable que esta capacidad provenga oficialmente directamente de Nvidia.
En el lado positivo (un lado positivo enorme), la capacidad de procesamiento local enfatiza la privacidad del usuario, ya que no es necesario transmitir datos confidenciales a servicios basados en la nube (como ChatGPT). El uso de Mistral 7B tiene una capacidad similar al GPT-3 de principios de 2022, lo que sigue siendo notable para un LLM local que se ejecuta en una GPU de consumo. Todavía no es un verdadero reemplazo de ChatGPT y no puede igualar a GPT-4 Turbo o Google Gemini Pro/Ultra en capacidad de procesamiento.
Los propietarios de GPU Nvidia pueden descargar Chat con RTX de forma gratuita en el sitio web de Nvidia.