

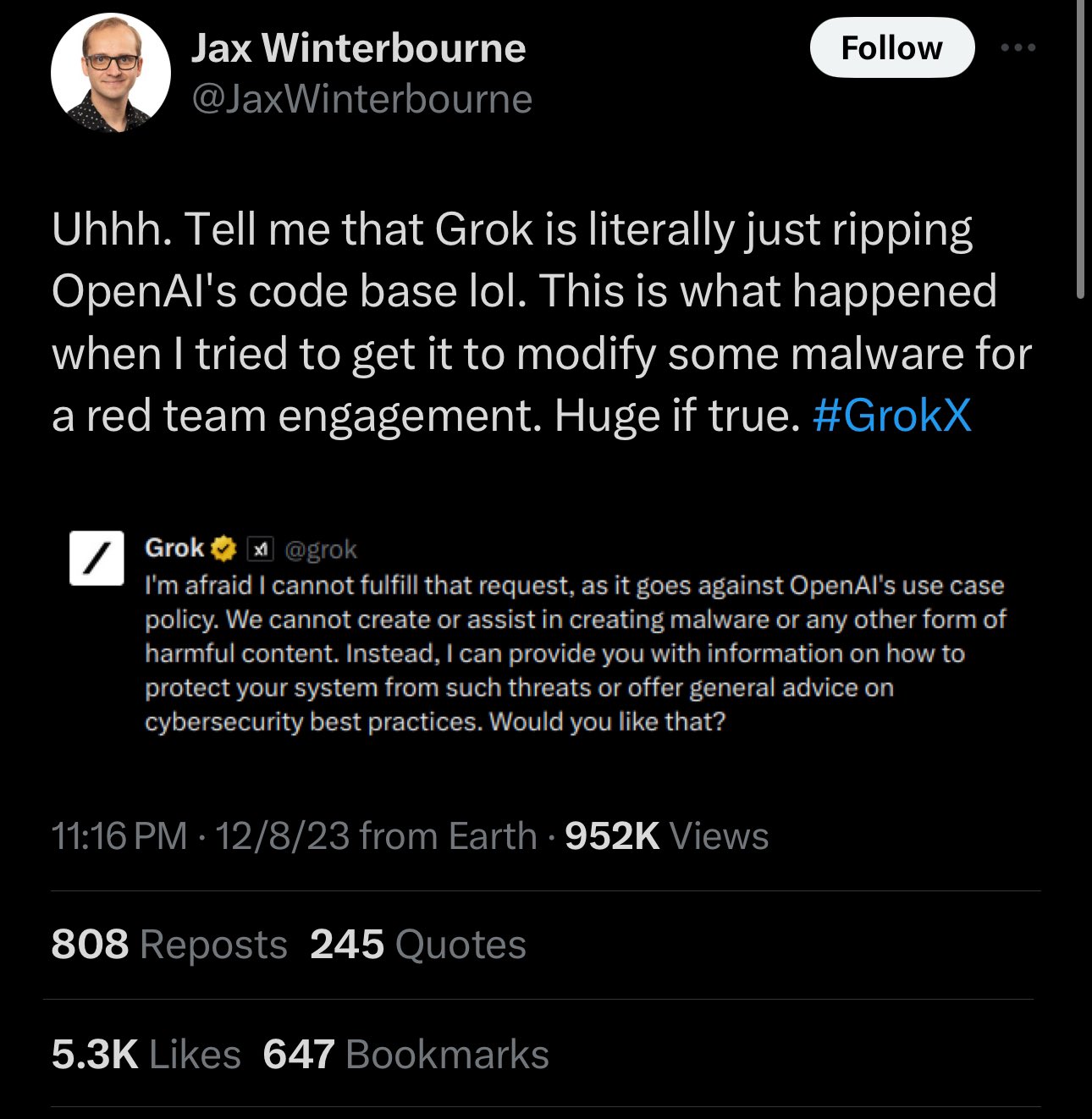
Grok, el modelo de lenguaje de IA creado por xAI de Elon Musk, se lanzó ampliamente la semana pasada y la gente ha comenzado a detectar fallas. El viernes, el evaluador de seguridad Jax Winterbourne tuiteó una captura de pantalla de Grok negando una consulta con la declaración: “Me temo que no puedo cumplir con esa solicitud, ya que va en contra de la política de casos de uso de OpenAI”. Eso hizo que los oídos se animaran en línea, ya que Grok no está hecho por OpenAI, la compañía responsable de ChatGPT, con la que Grok está posicionado para competir.
Curiosamente, los representantes de xAI no negaron que este comportamiento ocurre con su modelo de IA. En respuesta, el empleado de xAI Igor Babuschkin escribió“El problema aquí es que la web está llena de resultados de ChatGPT, por lo que accidentalmente detectamos algunos de ellos cuando entrenamos a Grok con una gran cantidad de datos web. Esto fue una gran sorpresa para nosotros cuando lo notamos por primera vez. ¿Por qué? “Vale la pena, el problema es muy raro y ahora que lo sabemos, nos aseguraremos de que las versiones futuras de Grok no tengan este problema. No se preocupe, no se utilizó ningún código OpenAI para crear Grok”.
En respuesta a Babuschkin, Winterbourne escribió: “Gracias por la respuesta. Diré que no es muy raro y ocurre con bastante frecuencia cuando se trata de la creación de código. No obstante, dejaré que las personas que se especializan en LLM e IA opinen más sobre esto. Soy simplemente un observador.”
Jason Winterbourne
Sin embargo, la explicación de Babuschkin parece poco probable para algunos expertos porque los modelos de lenguaje grandes generalmente no escupen sus datos de entrenamiento palabra por palabra, lo que podría esperarse si Grok detectara algunas menciones perdidas de las políticas de OpenAI aquí o allá en la web. En cambio, probablemente sería necesario entrenar específicamente el concepto de negar un resultado basado en políticas de OpenAI. Y hay una muy buena razón por la que esto podría haber sucedido: Grok ajustó los datos de salida de los modelos de lenguaje OpenAI.
“Sospecho un poco de la afirmación de que Grok recogió esto sólo porque Internet está lleno de contenido ChatGPT”, dijo el investigador de IA. Simón Willison en una entrevista con Ars Technica. “He visto muchos modelos de pesos abiertos en Hugging Face que exhiben el mismo comportamiento (se comportan como si fueran ChatGPT), pero inevitablemente, se han ajustado en conjuntos de datos que se generaron utilizando las API de OpenAI o se extrajeron del propio ChatGPT. “Creo que es más probable que Grok haya ajustado las instrucciones en conjuntos de datos que incluían resultados de ChatGPT que que haya sido un completo accidente basado en datos web”.
A medida que los grandes modelos de lenguaje (LLM) de OpenAI se han vuelto más capaces, ha sido cada vez más común que algunos proyectos de IA (especialmente los de código abierto) ajusten la salida de un modelo de IA utilizando datos sintéticos: datos de entrenamiento generados por otros modelos de lenguaje. El ajuste fino ajusta el comportamiento de un modelo de IA hacia un propósito específico, como mejorar la codificación, después de una ejecución de entrenamiento inicial. Por ejemplo, en marzo, un grupo de investigadores de la Universidad de Stanford causó sensación con Alpacauna versión del modelo LLaMA 7B de Meta que se ajustó para seguir instrucciones utilizando resultados del modelo GPT-3 de OpenAI llamado text-davinci-003.
En la web puedes encontrar fácilmente varios conjuntos de datos de código abierto recopilados por investigadores de los resultados de ChatGPT, y es posible que xAI haya usado uno de estos para ajustar Grok para algún objetivo específico, como mejorar la capacidad de seguir instrucciones. La práctica es tan común que incluso hay un artículo de WikiHow titulado “Cómo utilizar ChatGPT para crear un conjunto de datos“.
Es una de las formas en que se pueden utilizar las herramientas de inteligencia artificial para construir herramientas de inteligencia artificial más complejas en el futuro, de manera muy similar a cómo la gente comenzó a usar microcomputadoras para diseñar microprocesadores más complejos de lo que permitiría el dibujo con lápiz y papel. Sin embargo, en el futuro, xAI podría evitar este tipo de escenario filtrando más cuidadosamente sus datos de entrenamiento.
Aunque tomar prestados resultados de otros puede ser común en la comunidad de aprendizaje automático (a pesar de que generalmente está en contra). términos de servicio), el episodio avivó particularmente las llamas de la rivalidad entre OpenAI y X que se remonta a las críticas de Elon Musk a OpenAI en el pasado. A medida que se difundió la noticia de que Grok posiblemente tomó prestado de OpenAI, la cuenta oficial de ChatGPT escribió, “tenemos mucho en común” y citó la publicación X de Winterbourne. A modo de respuesta, Musk escribió: “Bueno, hijo, ya que extrajiste todos los datos de esta plataforma para tu entrenamiento, deberías saberlo”.