En respuesta a la controversia sobre los modelos de síntesis de imágenes que aprenden de las imágenes de los artistas extraídas de Internet sin consentimiento, y que potencialmente replican sus estilos artísticos, un grupo de artistas ha lanzado un nuevo sitio web que permite a cualquiera ver si su obra de arte se ha utilizado para entrenar a la IA.
El sitio web “¿He sido capacitado?“aprovecha la LAION-5B datos de entrenamiento utilizados para entrenar Stable Diffusion y Google Imagen Modelos de IA, entre otros. Para construir LAION-5B, los bots dirigidos por un grupo de investigadores de IA rastrearon miles de millones de sitios web, incluidos grandes repositorios
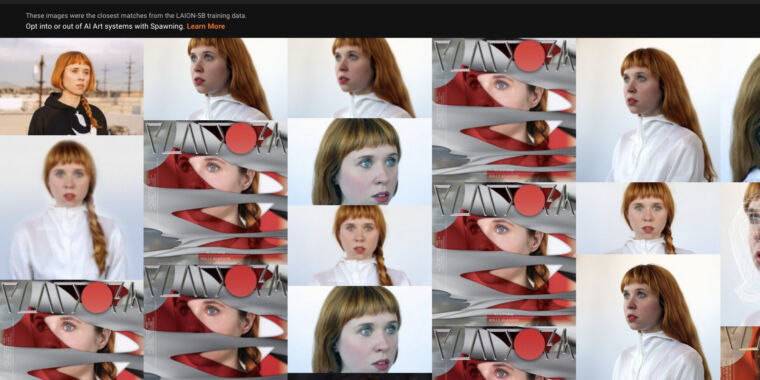
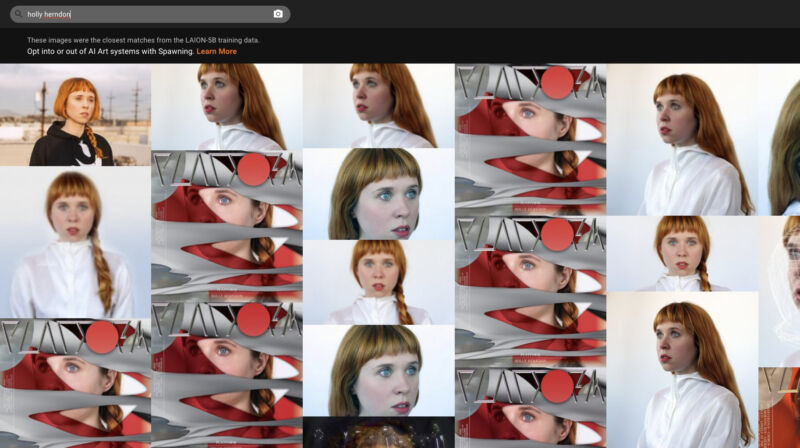
Al visitar la página ¿Me han capacitado? sitio web, que está a cargo de un grupo de artistas llamado Desove, los usuarios pueden buscar el conjunto de datos por texto (como el nombre de un artista) o por una imagen que cargan. Verán los resultados de las imágenes junto con los datos de subtítulos vinculados a cada imagen. Es similar a una anterior Herramienta de búsqueda LAION-5B creado por Romain Beaumont y un reciente esfuerzo por Andy Baio y Simon Willison, pero con una interfaz elegante y la capacidad de realizar una búsqueda inversa de imágenes.
Cualquier coincidencia en los resultados significa que la imagen podría haberse usado potencialmente para entrenar generadores de imágenes de IA y aún podría usarse para entrenar los modelos de síntesis de imágenes del mañana. Los artistas de IA también pueden usar los resultados para guiar indicaciones más precisas.
El sitio web de Spawning es parte del objetivo del grupo de establecer normas sobre cómo obtener el consentimiento de los artistas para usar sus imágenes en futuros esfuerzos de capacitación de IA, que incluyen herramientas de desarrollo que tienen como objetivo permitir que los artistas opten por participar o no en el entrenamiento de IA.
Una cornucopia de datos

Como se mencionó anteriormente, los modelos de síntesis de imágenes (ISM) como Stable Diffusion aprenden a generar imágenes mediante el análisis de millones de imágenes extraídas de Internet. Estas imágenes son valiosas con fines de capacitación porque tienen etiquetas (a menudo denominadas metadatos) adjuntas, como leyendas y todo el texto
Cuando escribe un mensaje como “una pintura de un gato de Leonardo DaVinci”, el ISM hace referencia a lo que sabe sobre cada palabra de esa frase, incluidas imágenes de gatos y pinturas de DaVinci, y cómo se organizan generalmente los píxeles en esas imágenes. en relación unos con otros. Luego compone un resultado que combina ese conocimiento en una nueva imagen. Si un modelo se entrena correctamente, nunca devolverá una copia exacta de una imagen utilizada para entrenarlo, pero algunas imágenes pueden ser similares en estilo o composición al material de origen.
Sería poco práctico pagar a los humanos para escribir manualmente descripciones de miles de millones de imágenes para un conjunto de datos de imágenes (aunque se ha intentado a una escala mucho más pequeña), por lo que todos los datos de imágenes “gratuitos” en Internet son un objetivo tentador para los investigadores de IA. No buscan el consentimiento porque la práctica parece ser legal debido a Decisiones judiciales de EE. UU. sobre el raspado de datos de Internet. Pero un tema recurrente en las noticias de IA es que el aprendizaje profundo puede encontrar nuevas formas de usar datos públicos que no se habían anticipado anteriormente, y hacerlo de maneras que podrían violar la privacidad, las normas sociales o la ética de la comunidad, incluso si el método es técnicamente legal. .
Vale la pena señalar que las personas que usan generadores de imágenes de IA generalmente hacen referencia a artistas (generalmente más de uno a la vez) para fusionar estilos artisticos en algo nuevo y no en una búsqueda para cometer una infracción de derechos de autor o imitar nefastamente a los artistas. Aun así, algunos grupos como Spawning sienten que el consentimiento siempre debe ser parte de la ecuación, especialmente cuando nos aventuramos en este territorio inexplorado y en rápido desarrollo.